

AWS Backup has recently added S3 to the range of supported services in AWS Backup which means you can now use backup to automate the backup of objects and files stored in Amazon S3.
Using AWS Backup you can centrally automate the backup and restore of data stored in S3 along with other compute, storage and database services that are already supported by AWS Backup.
Using the seamless integration with AWS Organizations, you are able to create a centralized data protection policy to help protect and recover your data when it is inadvertently corrupted, deleted by mistake or subjected to malicious actions.
Data secured by AWS Backup can be restored to specific points in time with a few simple clicks giving you the ability to reinstate data at a desired point in time.
A side benefit of setting up AWS Backup for your organisation is that you have the data protection receipts to prove governance compliance with auditor ready reports available on demand to show how and when your data is being protected.
The immutable backups of your S3 data can span multiple accounts and multiple AWS regions which means even if an entire region or account goes down, your backup administrators have a pathway to recovery.
AWS Backup for Amazon S3 is available in the following regions (at time of writing)
- US East - Ohio
- US East - North Virginia
- US West - Northern California
- US West - Oregon
- Africa - Cape Town
- Asia Pacific - Hong Kong
- Asia Pacific - Mumbai
- Asia Pacific - Osaka
- Asia Pacific - Seoul
- Asia Pacific - Singapore
- Asia Pacific - Sydney
- Asia Pacific - Tokyo
- Canada - Central
- Europe - Frankfurt
- Europe - Ireland
- Europe - London
- Europe - Milan
- Europe - Paris
- Europe - Stockholm
- Middle East - Bahrain
To get started with AWS Backup for S3 is reasonably straightforward and you have the option of using the AWS Backup Console, manually using the CLI or programmatically using SDKs.
Using the AWS Backup Console to backup S3.

There are two initial steps required to set up your AWS Backup to start protecting your S3 data. You will need to create a backup plan that defines your schedule, retention and lifecycle rules and then you need to assign resources to the backup plan using resource tags or AWS resource IDs.
You can then use the AWS Console to centrally manage your backup configurations, monitor backup activity and initiate restores from the backups when necessary.

When you start to create a plan, you will have the option of selecting an existing template, building a new plan from scratch, or modifying the JSON of an existing backup plan during which you can ingest JSON data to create a plan.
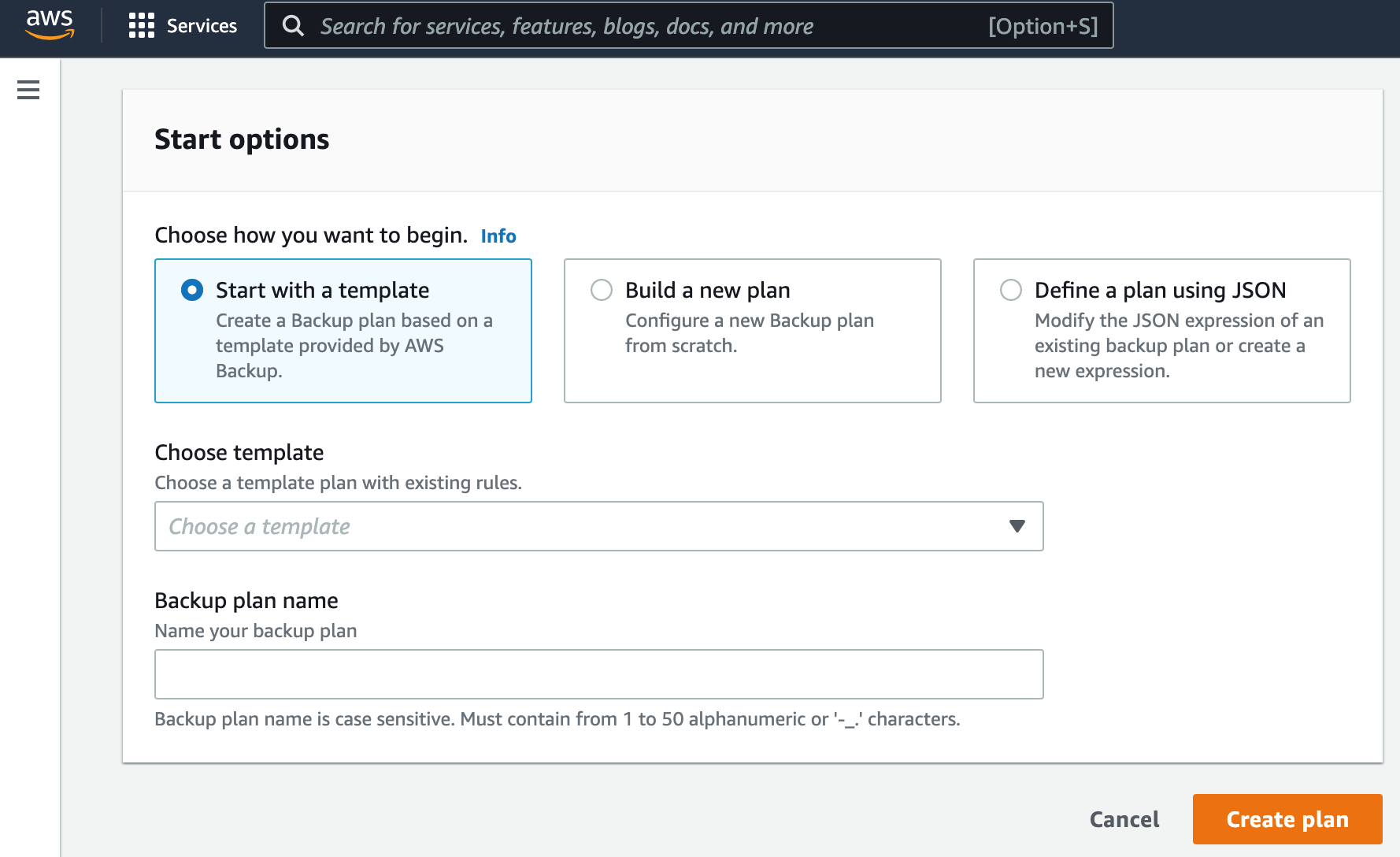
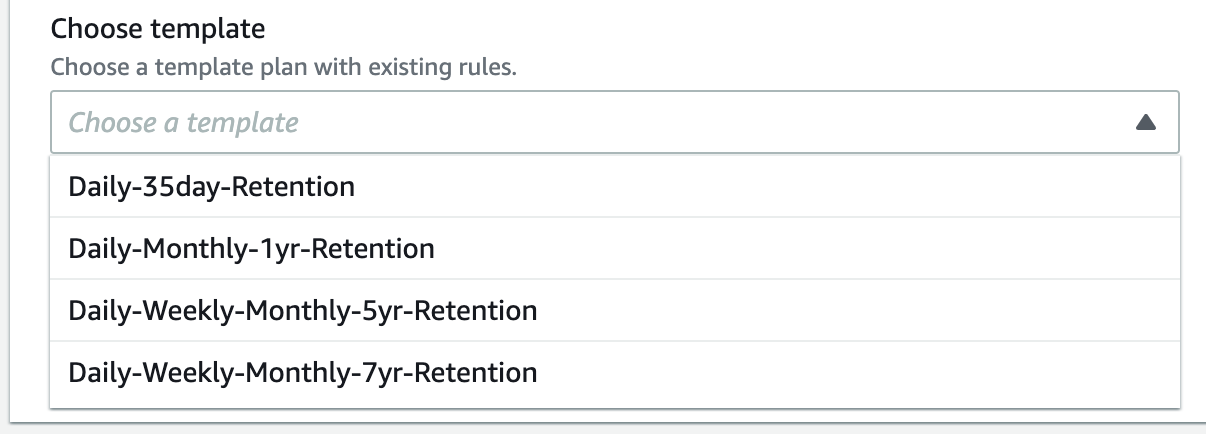
The pre-existing plan templates provided by AWS include a daily backup retained for 35 days, monthly backups retained for a year and several others.
Once you have chosen what type of plan to build, you can name your new backup plan.
For our example, we’ll set up a custom plan built from scratch called My_S3_Backups.
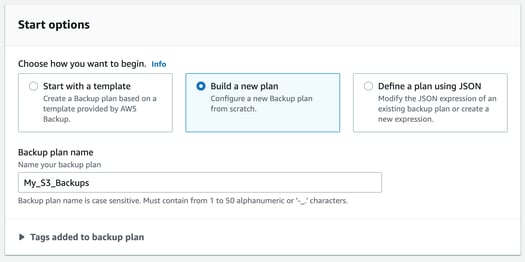
With the name and “build a new plan” selected we are then prompted to create a backup rule. This rule will be applied to the plan we are creating, but can also be applied to other plans later.
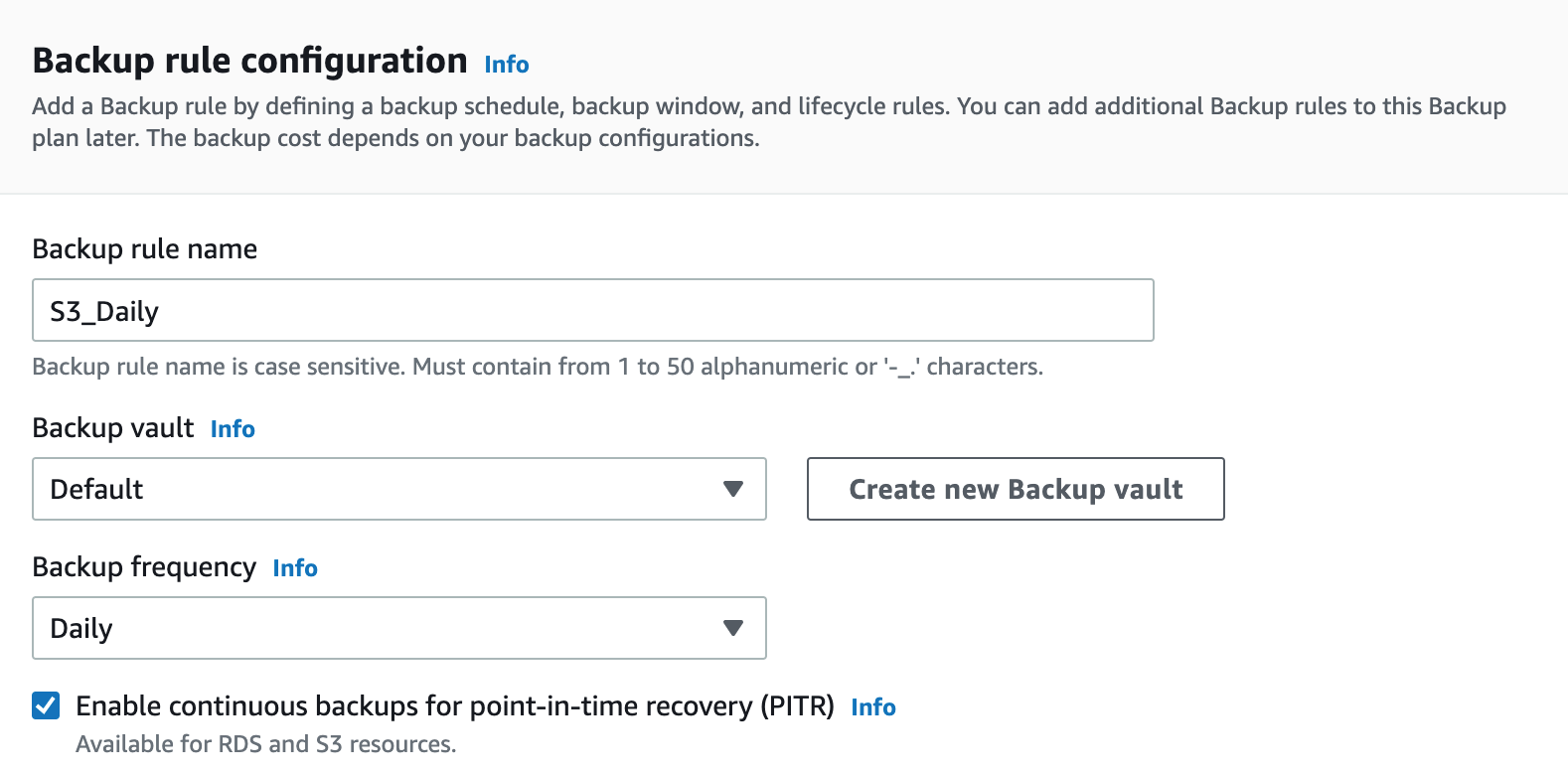
We need to name the rule, in this case we’ll call it S3_Daily.
We can at this point create a new backup fault, or leave it as Default.
We then need to select the backup frequency, which in this case is Daily.
We also have the option at this stage to select Point In Time Recovery (PITR) which will enable us to specify specific versions of files to restore based on time they were backed up.
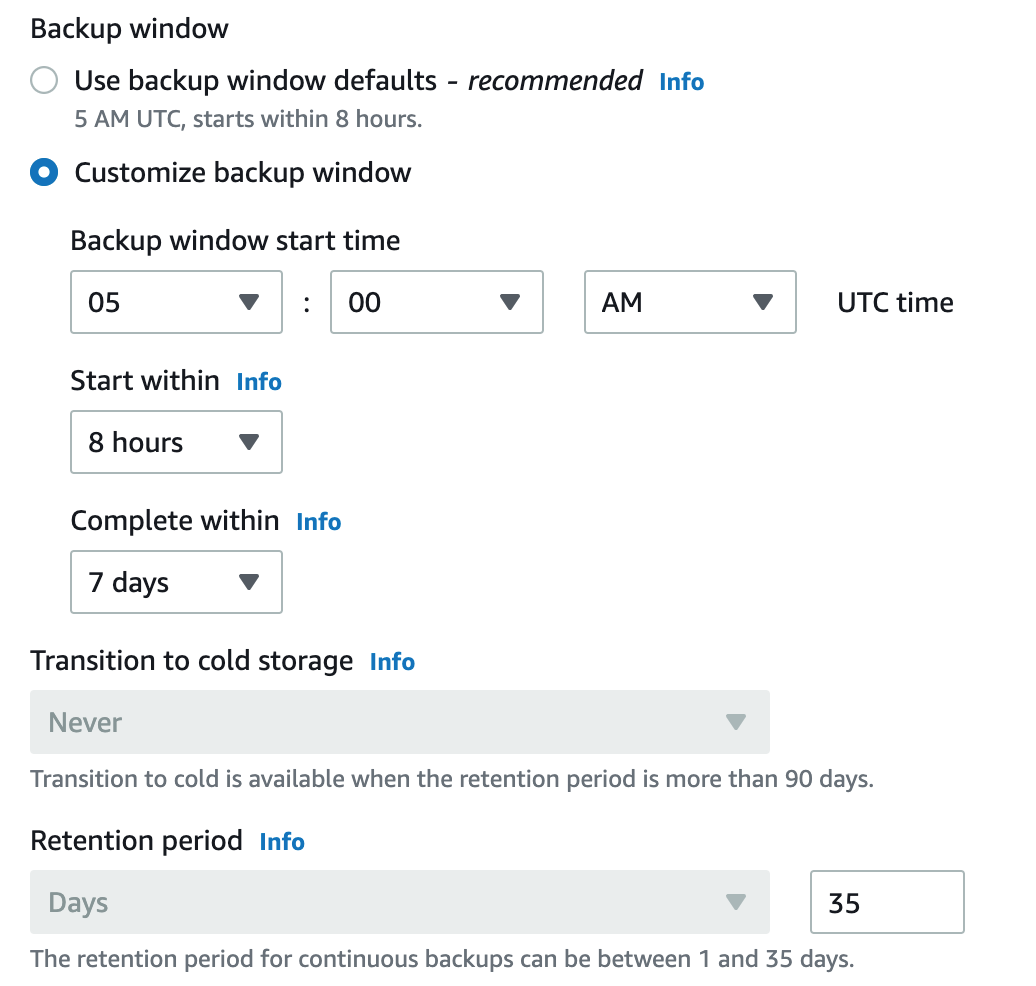
You can then specify the backup window. AWS recommends using the default which is 5am UTC or you can customize the time window for your backups.
Here you also have the ability to transition retained backups to cold storage if your backups are retained for more than 90 days.
In our case, the retention period for continuous daily backups with PITR enabled is 35 days with no option to cold store them.
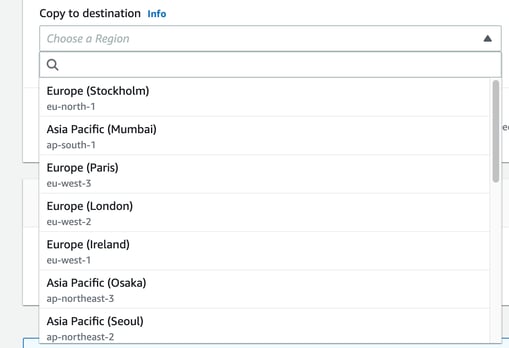
You then need to nominate a region to hold your backup.
Finally you can nominate to store the backups in another AWS account or use your account’s default vault or you can create a new backup vault at this point.
You can now create the plan.
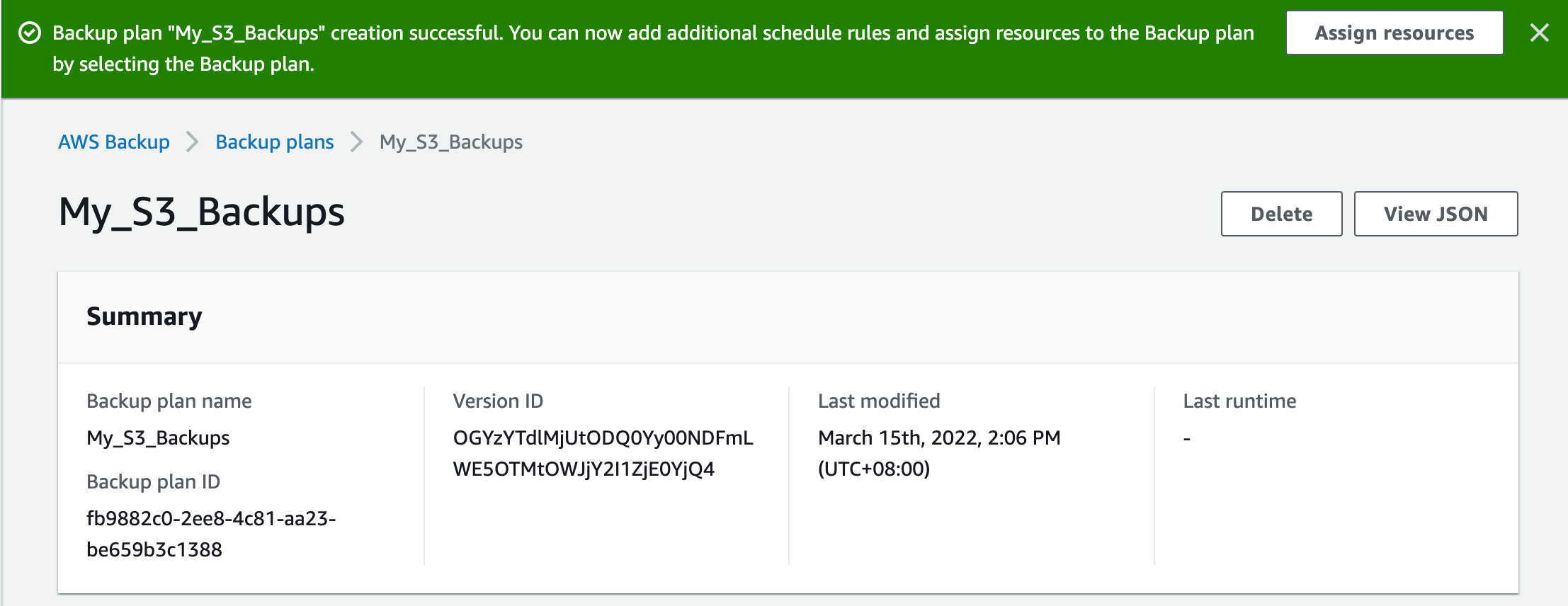
Assign Resources
The next step is to assign resources.
You can assign a specific IAM role to perform the backup or leave it at the account default
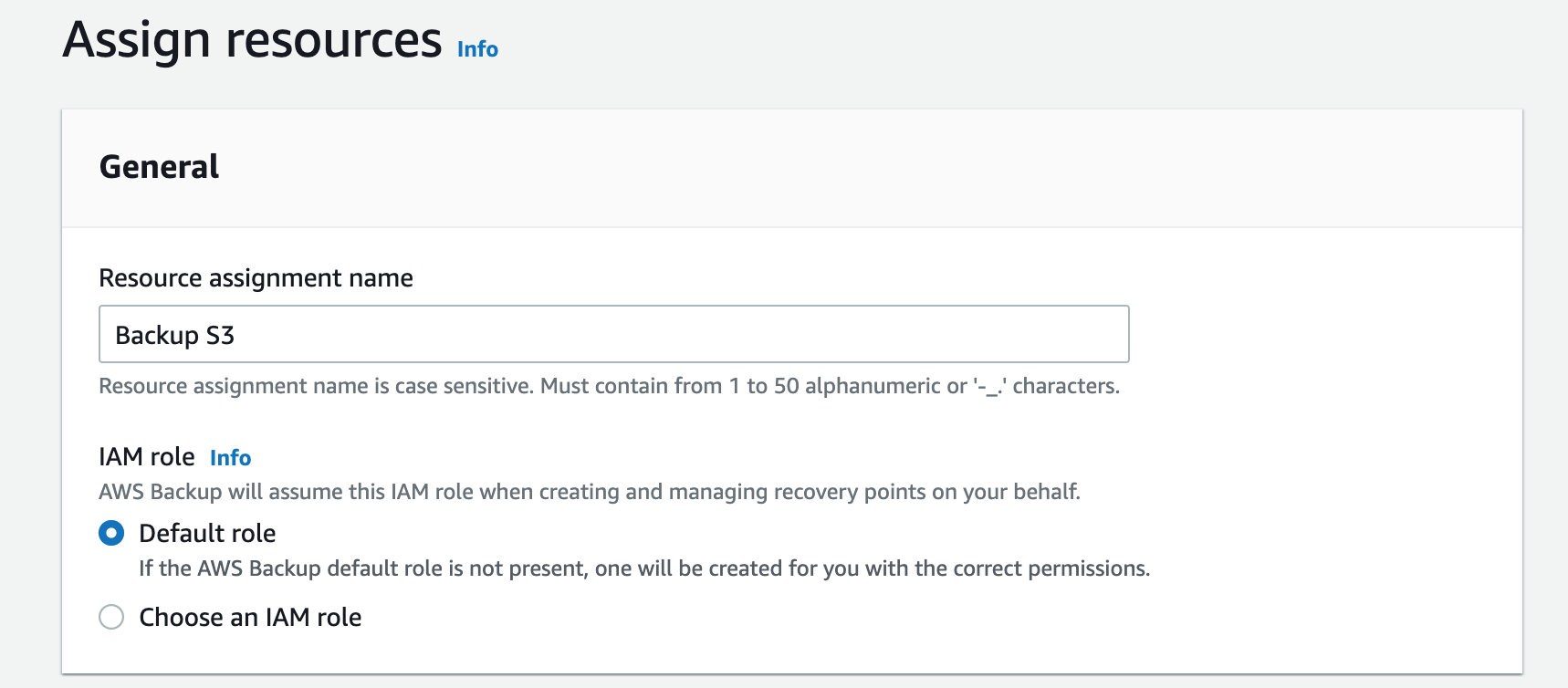
The next step is to assign resources. You are able to include all eligible resource types or manually select specific resource types:
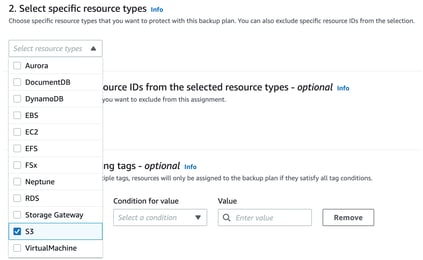
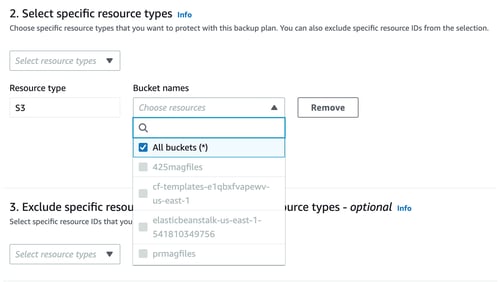
When S3 is selected, you can now specify which buckets to include. With PITR selected, the S3 buckets need to have versioning enabled.
You can also specify specific resource IDs to exclude.
Finally, you can define the tags you wish to use to control exactly what gets backed up. Select an existing tag from the key drop down, enter the condition to be met (ie equals, begins with etc) and then select the value that needs to be met. You can enter up to 30 tags.
Obviously all the tags should be established prior to setting up the backup, however you can assign more tags or resource IDs to a backup schedule after it has been created.
The JSON for the backup policy looks something like:
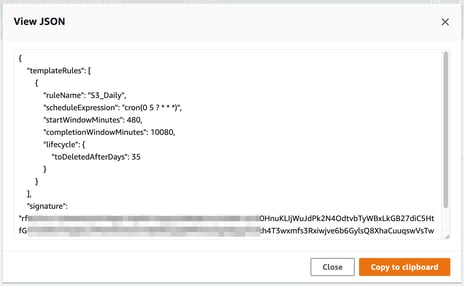
AWS Backup Billing
AWS charges for the amount storage used for your backup data and charges for any data restored during the month.
For the initial backup a full copy of your data is backed up and charged for. Subsequent to that, AWS only backs up incremental file changes and charges for just that data, not the entire backup set.
The billing amount is based on the average amount of data stored during any given month.
Charges vary depending on the region being used.
For example US East (North Virginia) charges at time of writing are:
- $0.05 per GB-month for EFS, EBS, Storage Gateway Volumes, FSx, S3, VMware
- $0.021 per GB-month for Aurora, DocumentDB Cluster, Neptune
- $0.10 per GB-month for DynamoDb table backup
- $0.095 per GB-month for RDS Database snapshots
So that’s a run through a simple example of how to use AWS backup to back up your S3 data alongside the other services traditionally integrated with AWS backup.
If you are building solutions on AWS, you can use Hava to automatically generate network topology diagrams, security group and container workload diagrams and AWS compliance reports by simply connecting your AWS account to Hava (either via SaaS online or self hosted on your own infrastructure). Which means you always have up to date, accurate self-updating information on what VPCs you have running, what resources are running in them and you can tell visually if they are as secure as you imagined.
You can take a free 14 day trial of Hava, learn more here:


