S3 Optimization
Some organisations struggle to contain their S3 Storage costs through a combination of failures around planning and monitoring. This could be due to the complete absence or incomplete application of both important steps.
Typically organisations struggle with containing their AWS S3 costs in a number of areas.
No Accurate assessment of their Application’s requirements.
Missing or incomplete analysis of what their app requires in terms of storage both initially and as usage scales.
Poor Planning.
Some organisations fail to consider existing data access requirements, usage patterns or evolving storage needs.
Missing Storage Management
Lack of an effective method of managing and moving data.
Inability to Monitor
The organisation has no method of accurately monitoring storage levels.
AWS point out that there are four pillars of cost optimization to consider to ensure you manage all aspects of your data stored in S3
Pillar 1: Application Requirements
Before you start to address storage costs by introducing cost optimization strategies, you really need to understand your application workloads, data lifecycles and what data access is required. Understanding how and when your application accesses data, how long information is retained, any archiving requirements due to governance concerns and when data can be deleted all have a bearing on how you manage your storage costs.
Pillar 2: Data Organisation.
Putting some effort into data organisation by introducing naming conventions and/or tags allows you to manage your data object lifecycle at a granular level. Knowing the state of your data allows you to effectively optimize costs.
Pillar 3: Understand, Analyze and Optimize.
Proactive cost monitoring and observing data usage patterns help organizations understand how they are using data storage and can inform the selection of the best storage class based on performance and cost.
Pillar 4: Continuous Right Sizing
Right sizing is the process of selecting the correct storage class for your data. There are a number of Amazon S3 storage classes designed for different use-cases. Higher performance options will come at a price, so establishing the best storage for your application is essential. The first step is understanding your data requirements and ensuring that you have selected the right class for your requirements from a performance and cost perspective.
Understanding your data access patterns.
New AWS services and features are being released all the time. What was once the best and most optimal storage option for your business may have been superseded by a newer, faster, cheaper option. So it’s essential to continuously monitor your workload and data usage patterns to ensure you have the best storage options for your applications.
AWS provides a number of tools to help determine your data classification and access patterns which can vary depending on whether your workloads are predictable or unpredictable.
For predictable workloads, Amazon S3 Storage Class Analysis tool observes your data access patterns over a time period and the findings can be used to adjust lifecycle policies so you can transition data to less frequently accessed often cheaper storage classes.
Unpredictable workloads can benefit from Amazon S3 intelligent tiering, which moves data between four separate access tiers being a high availability frequent access tier, an infrequent access tier which are both online which are complimented by archive and deep archive tiers for cold data.
This intelligent tiering provides a level of automatic cost optimisation should your team lack the time and resources to manually fine tune your storage requirements especially if your data access patterns fluctuate.
By moving data from frequent to infrequent access tiers you may be able to realise a 40 percent cost reduction. When S3 Glacier and S3 Glacier Deep Archive tiers are utilised, you may see cost savings of up to 95 percent over storing data permanently in high availability frequent access storage.
Organizing and Managing Data Manually
Another key component of managing costs is implementing a tagging strategy to organize data. Being able to identify data allows granular and improved insights into your usage and the ability to apportion costs based on applications, projects or entire teams. Cost allocation tags allow you to identify and group costs on your cost allocation reports.
Tools that can help understand data access and usage

Amazon S3 Inventory
This tool allows you to identify and audit storage including replication and the encryption status of objects for compliance and regulatory needs.
Amazon S3 Server Access Logging
S3 Server Access Logs provide detailed information about the requests that are made to each S3 bucket and can be useful in many scenarios such as security and data access audits. They can also help you understand how your users are accessing data and contribute to your S3 costs.
CloudTrail Logs
AWS CloudTrail is a service that provides compliance, operational auditing and provides a governance framework for your AWS account. You can use CloudTrail to continuously monitor and store account activity related to actions across your AWS infrastructure detected through console activity, CLI, SDK and other AWS services.
Identifying savings using the above tools is possible by using S3 Inventory to determine which objects are in your S3 buckets. Server access logs and CloudTrail logs help determine which objects are not being accessed. These objects can then be moved to archived tiers for storage cost savings.
AWS provides a number of tools to assist with the visualization of S3 storage, data access patterns and cost.
Monitors access patterns across objects to help you decide when to transition data to the appropriate storage class. You can then use the S3 lifecycle policy to make the data transfer to the appropriate storage class.
The tool also provides daily visualizations of your storage usage on your AWS management console that you can export to S3 for use with other BI tools.
Configuration involves deciding what you want to analyse. Selecting an entire bucket, the tool will analyze the contents of the bucket, returning details for every object in the bucket.
Prefixes and tags can be used to group objects together for analysis, to a maximum of 1000 filter combinations per bucket. You’ll receive separate analysis for each filter you create.
Once you configure storage class analysis, you’ll need to wait 24 hours for the report and new reports will be generated daily. Reports can be sent to an S3 bucket in CSV form that can be imported into analysis applications like Amazon QuickSight

Amazon QuickSight
AWS QuickSight facilitates the visualization of S3 data by allowing you to create interactive BI dashboards that can be embedded into apps, portals and websites.
You can access visualizations through the S3 console without the need for manual exports.
To use QuickSight you’ll need to enable Storage Class Analysis for your buckets.
Once you have Storage Class Analysis feeding back information, you can configure lifecycle policy rules to move infrequently accessed data to the cheaper storage tiers.

S3 Storage Lens
Provides actionable recommendations to improve cost-efficiency and data protection whilst providing visibility into storage usage, activity and trends.
Storage Lens aggregates your usage and activity metrics and displays the information on your S3 console, or optionally export to CSV. Data is retained for 15 months.
You can use the dashboard to see trends and insights, flag outliers and view the recommendations generated by storage lens to optimise costs and also apply data protection best practices.
Usage metrics like size, quantity and characteristics of your storage are free however activity metrics like access requests, request types and upload/download stats attract an AWS fee. You need to activate advanced metrics.
Optimization recommendations are displayed alongside metrics in the storage lens dashboard for current configurations.
Advanced metrics subscribers will also receive call-outs from Storage Lens when anomalies are detected in your storage or access activity.

Amazon CloudWatch
This monitoring service provides infrastructure wide recommendations by monitoring application health, system-wide performance and resource usage.
Cloudwatch has a free tier and can receive usage data from S3.
The free tier metrics are reported daily and include the number of objects in a bucket for all storage classes except S3 Glacier and reports the amount of data stored in a bucket irrespective of storage class.

AWS Budgets
Using AWS budgets, you can set custom budgets across projects, individual resources, tagged and untagged. You can set alerts and receive email, sms or messenger messages as budget milestones are exceeded by actual cloud spend.
You can set a fixed target budget to track all costs associated with your AWS account.
It is also possible to set a variable budget that increases month on month and configure notifications based on when your cloud spend reaches specific milestones.
Interestingly it is possible to attach an IAM policy that is applied as a notification is triggered, for example you could block provisioning additional resources for an account that has gone over budget.

AWS Cost and Usage Reports
CUR Provides reports on billing and usage, which can be enhanced by implementing a good tagging regime.
The reporting is the most comprehensive source of billing information for S3 and other AWS resources and can be downloaded from your S3 Console.
Cost allocation tags can be added to individual AWS resources in order to assist with categorizing cloud spend into your desired grouping, whether that’s department, project, owner, application. Tags are user generated metadata and are only limited by the resources you have provisioned, including S3 Buckets.
Usage reports are dynamically generated and allow you to choose usage types, operations and date/time ranges and are downloadable as XML and CSV
S3 Lifecycle Policies
S3 provides the ability to manage objects to take advantage of more cost effective storage tiers as data moves through its lifecycle. As well as transitioning data to cheaper storage, lifecycle management also allows you to create rules to delete objects based on age.
There are a number of reasons why you would create rules to move objects between storage tiers. Cost savings is a major motivation for setting up lifecycle configurations, however retention durations can also drive the need to retain or archive data depending on the business case or need to meet compliance guidelines.
If you know your access patterns and they follow a consistent pattern, then tackling S3 LifeCycle configuration is feasible. If you don’t have a good understanding of how your data access patterns are shaped or if they are inconsistent then it may be better to take advantage of S3 Intelligent-Tiering storage. This automates the movement of data to the most cost effective storage tier based on access patterns.
Manual S3 lifecycle rules allow you to transition object data larger than 128KB from S3 Standard Storage to lower storage classes, but do not provide the ability to move object back to the standard storage tier.
LifeCycle Configuration Rule Use Cases
There are many reasons to move objects to more cost effective storage tiers as demand for the files or data diminishes.
Logs files for instance are typically stored in a bucket and interrogated for dashboard or reporting processes for a week or two. After this time period, the log data may no longer serve a purpose and can be archived and ultimately deleted.
Some projects and processes require documents that are frequently accessed for the duration of the project or over a short period of time. These documents may then be infrequently accessed on completion of the project. These files are prime candidates for archival and ultimately deletion as any retention period expires.
S3 itself is often used as an archival repository for database backups, archived documents and data needed for regulatory, governance or compliance purposes. This ‘just-in-case’ data may never be accessed again, so can happily reside in a S3 Glacier or Deep Archive.
To provide more control, it is possible to have separate S3 Lifecycle configs for both versioning-enabled buckets and unversioned buckets as well as separate rules for the current and non-current object versions.
Object expiration once defined will trigger S3 to mark objects for deletion. Once flagged, S3 periodically passes through your S3 buckets removing flagged objects.
Lifecycle configuration isn’t supported on MFA enabled buckets and Lifecycle actions triggered by the rules you define are not captured by AWS Cloudtrail object level logging, you’ll need to refer to your S3 Server access logs to review lifecycle-related actions.
Creating Lifecycle Rules
Adding rules to S3 lifecycles is reasonably straightforward.
Navigate from your AWS console to Storage > S3
Then select the desired bucket and open the Management tab.
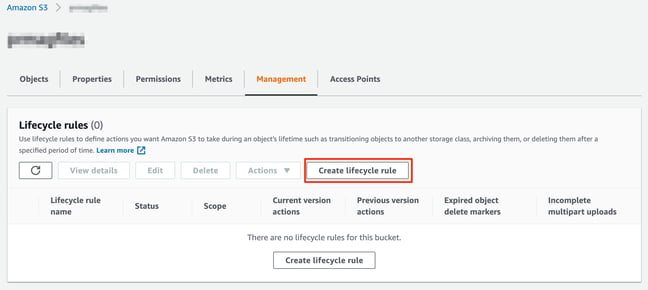
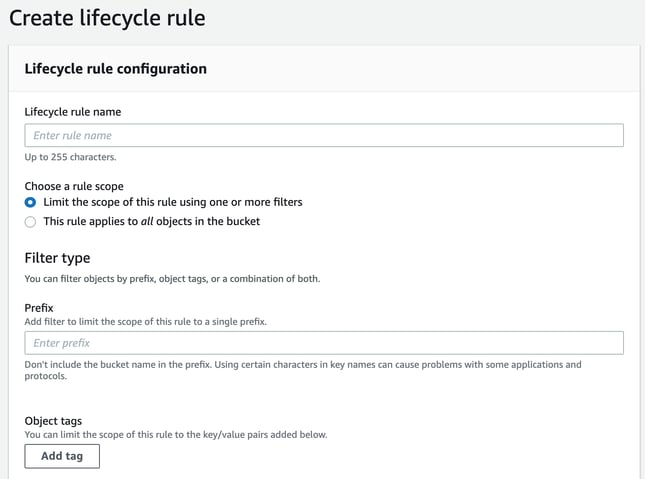
Name the new rule and define whether it applies to specific prefixes or object tags, or if it applies to all objects within the S3 bucket.
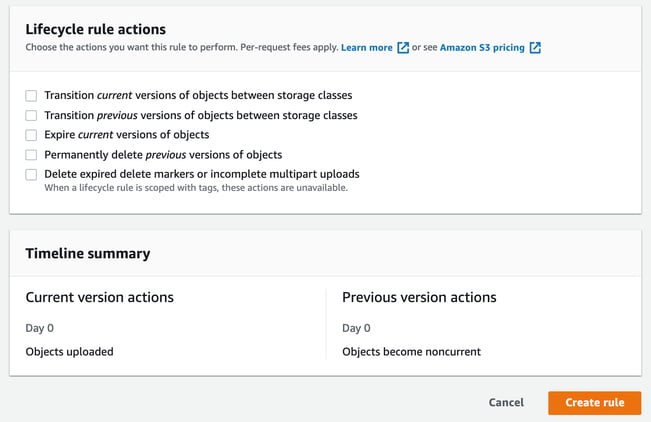
Select and specify the actions you want to apply and create the rule.
Amazon S3 Storage Classes
As of writing, the available S3 storage classes are:
S3 Standard - offers high durability and availability for frequently accessed data
S3 Intelligent-Tiering - Automatically moves data to the most cost effective storage tier.
S3 Standard-IA - Infrequent access. Designed to hold less frequently accessed data that is still required to be served quickly when needed
S3 One Zone-IA - A 20% lower cost option for infrequently accessed data that stores data in a single availability zone instead of the normal minimum 3 AZs. Typically used for secondary back ups or as a target for cross-region replication.
S3 Glacier - provides low cost durable storage that can be used to receive data triggered by lifecycle actions. Three retrieval options are available, ranging from a few minutes to a few hours.
- Expedited retrieval (1 - 5 mins)
- Standard retrieval (3-5 hours)
- Bulk retrieval (12 hours)
Data in glacier is stored across 3 or more AWS AZs and can be moved to Deep Archive.
S3 Glacier Deep Archive - The lowest cost storage option available, for long term storage of data that may need to be accessed once or twice a year. Viewed by AWS as an easier to access and manage alternative to magnetic tape offsite storage, data that is stored on S3 Glacier Deep Archive can take upwards of 12 hours to retrieve.
Objects sent to S3 Glacier Deep Storage need to be stored for a minimum of 180 days and is stored across 3 or more AWS AZs.
Both S3 Glacier tiers can be directly uploaded to, however for objects larger than 100MB AWS recommends using multi-part uploads.
Summary
AWS provides you with all the necessary analysis and reporting tools to establish your S3 usage and helps identify the objects sitting in S3 buckets that may be generating more storage costs than is necessary.
Leveraging S3 Intelligent Tiering or setting up lifecycle management rules to your S3 storage buckets while somewhat tedious, may provide the opportunity to significantly reduce your cloud storage costs.
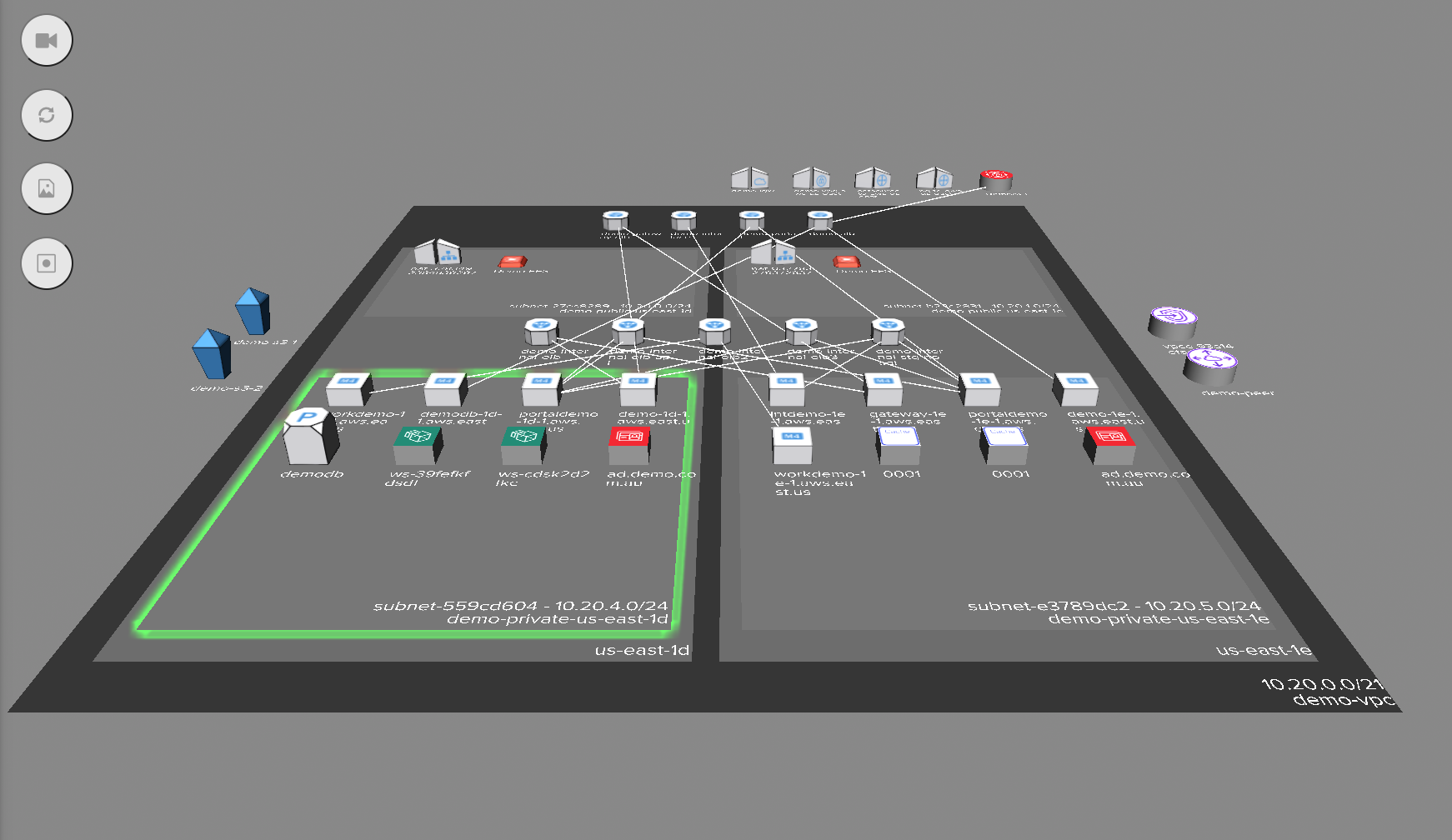
Using Hava you can easily identify your S3 storage buckets. Using the custom search query it is possible to visualize all your S3 buckets from all the AWS accounts you have connected to Hava on a single diagram and view the metadata related to each bucket.
Should you undertake the task of manually setting lifecycle policies for all your S3 buckets, it would be possible to tag S3 buckets as they are addressed and then exclude the tagged resources in subsequent Hava infrastructure diagrams so you are able to easily identify the S3 buckets without lifecycle policies in place.

You can check out Hava automated cloud diagrams by creating a free trial account: