

Amazon Athena is a service that enables you to perform SQL queries on data held in amazon S3. There are no complex ETL pipelines to create which makes Athena perfect for anyone with SQL skills to analyse large amounts of data without having to extract and prepare data held in S3.
Athena is serverless and there is no requirement to provision resources to perform the query workloads, you simply execute search queries and AWS charge you on a per query basis. There is no need to provision servers, set up data warehouses and ingest data.
You simply point Athena to your data in S3, define the schema and start querying using standard SQL or using the Athena built in query editor.
Athena is also natively integrated with AWS Glue data catalog so can operate against a metadata repository gathered from multiple sources.
Athena utilizes Presto, an open source distributed query engine designed for super fast analytics queries against large data sets. Built on Hadoop, Presto leverages multiple worker nodes in parallel.
Behind the scenes, Amazon Athena deploys Presto using the AWS Serverless platform, with no servers, virtual machines, or clusters to set up, manage, or tune. Simply point to your data at Amazon S3, define the schema, and start querying using the built-in query editor, or with your existing Business Intelligence (BI) tools. Athena automatically parallelizes your query, and dynamically scales resources for queries to run quickly.
Presto supports ANSI SQL and works with several data formats like CSV, JSON, ORC, Parquet and Avro which makes it ideal for on the fly interactive querying as well as complex analysis involving large joins and arrays.
Because you are charged per query, AWS provides an interactive visualization (one of our favorite things) of the query plan. This will inspect the operators, joins and data that will be processed at every step of the query.
Once your query is processed the visual query analysis tool will show query metrics that show the amount of time spent in the queuing, planning and executing phases as well as the rows and size of the data returned by the query. The visualisation results are embedded in the console but can also be accessed via the query statistics API.
Athena Table Definitions and Schema
Athena uses a managed data catalog to store information that defines the data in the storage you intend to query. If AWS Glue is available in your region, you can choose to utilise the AWS Glue Data Catalog instead.
Modification of the catalog can be done via Data Definition Language (DDL) statements or using the Athena Console to define the underlying S3 data.
The data definitions are only used when executing queries and are independent of the actual stored data, which means you can delete or modify definitions without impacting the underlying data.
Creating Tables, Data Formats and Partitions for Amazon Athena
Athena utilises Apache Hive DDL to define tables as well as modify and delete them. This is typically done in the Athena console or using ODBC or JDBC drivers via API. You can also use the Athena create table wizard in the Athena Console.
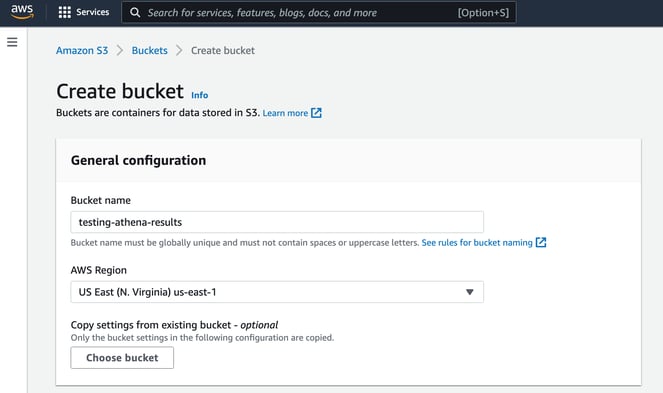
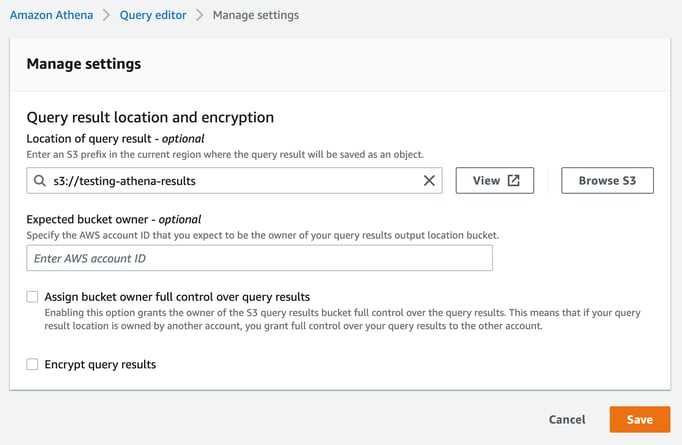
The first thing to establish is a S3 bucket to receive the query results, in this example we’ll use “testing-athena-results”
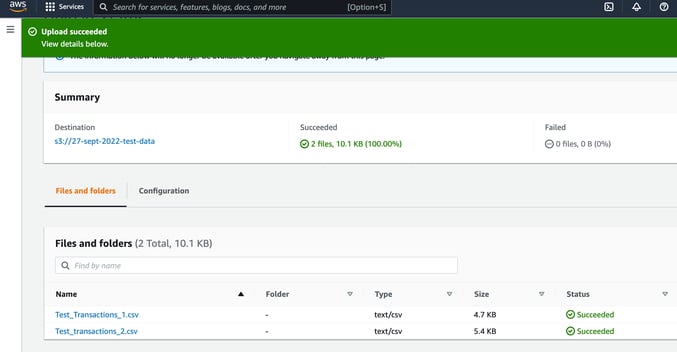
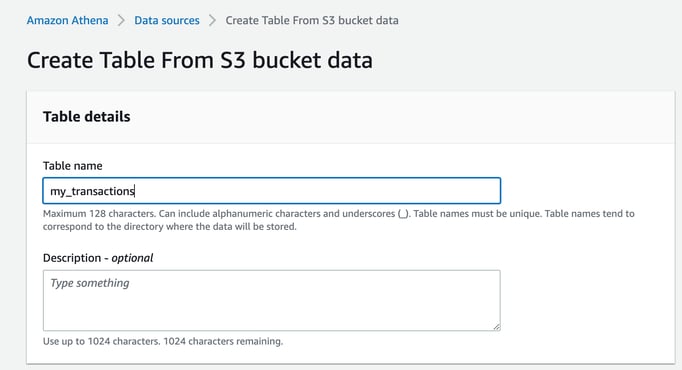
The we will upload a couple of CSV files containing transaction information into a bucket called “27-sept-2022-test-data”
When you first open the Athena console you will get a warning that you need to establish a query result location.
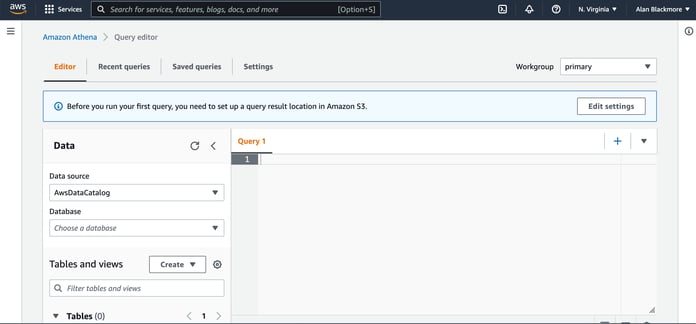
Here you enter the S3 bucket location, which in this example is the “s3://testing-athena-results” bucket we just created.
You can also enter an optional AWS account ID of the expected owner of the results bucket. In this instance that’s us, so we can leave it blank.
The next step is to create a database that you can use to create tables used to map the file contents schema to.
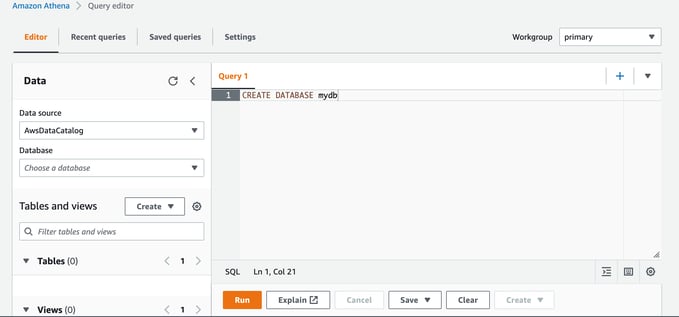
This makes the new “mydb” database available in the Database selection box in the left hand dialogue side panel.
Now next to the Tables and Views select “create” and “S3 Bucket Data”
This will launch a wizard:
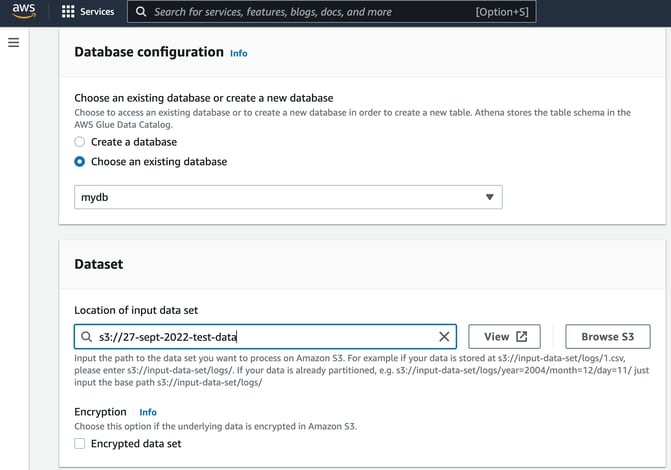
Select the database you want to store the schema in and then enter the location of the input data set, in this case it’s our “s3://27-sept-2022-test-data” bucket.
Next you can specify the data format of the files in the bucket. We’ll choose CSV
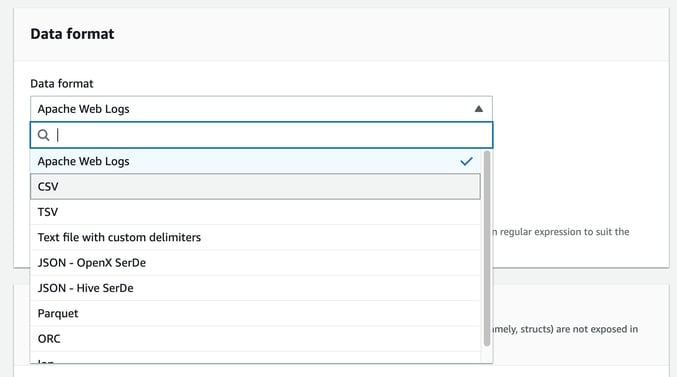
Here you can currently select from :
- Apache web logs
- CSV
- TSV
- Text file with custom delimiters
- JSON OpenX
- JSON - Hive SerDe
- Parquet
- ORC
- Ion
The wizard will now display the query built to create the table that maps to the contents of our CSV files.
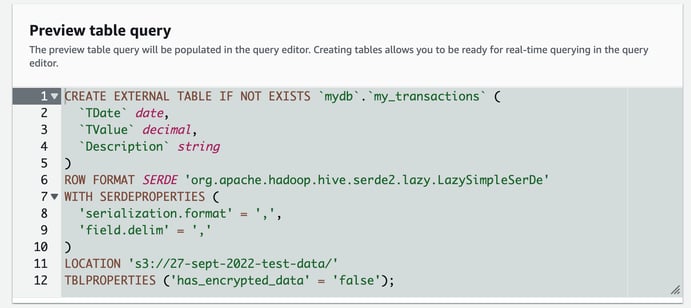
Now you can create the table and you have a table that you can execute SQL queries on that will apply the query to the files contained in the S3 bucket specified.
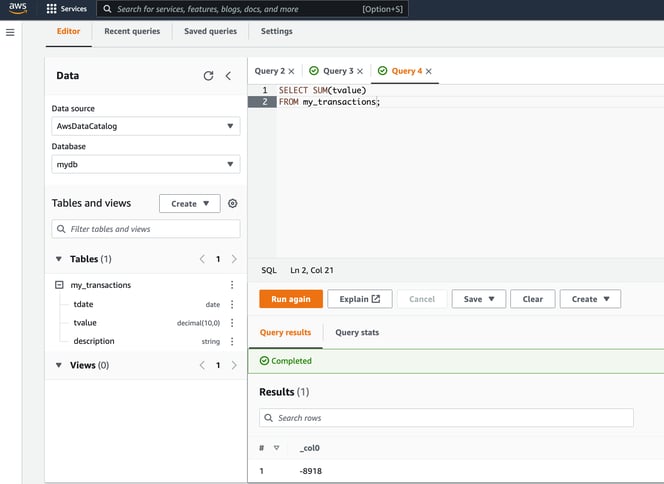
Obviously this is as simple an example as you get, but hopefully it gives you a better idea of what Amazon Athena is and how to get started,
There are many different data sources beyond S3 that you can connect Athena to and also many business intelligence and analysis tools you can connect to Athena to do deeper and more complex data analysis.
If you are building solutions and storing data on AWS, you can use hava.io to visualise your AWS VPCs and infrastructure. By connecting to Hava, your infrastructure, security and container diagrams will be automatically created and kept up to date automatically to.
You can export your diagrams in a number of formats or embed live interactive diagrams externally in web properties, wikis like confluence or into github documents using plug ins and actions that come with Hava.

You can open a Hava account and connect using the button below. When you sign up, you'll receive a free 14 day trial of the fully featured teams plan so you can try out all the advanced features at your own pace.



