

AWS Glue is a fully managed serverless ETL (extract, transform, load) data integration service you can use to ingest, prepare and combine data from multiple sources. Once in Glue, your data can then be used for analytics purposes, fed into machine learning processes or used with applications you develop.
Glue contains all of the capabilities required to integrate data from different sources so you can get on with the job of analysis and enjoy the results in minutes.
You have the choice of a visual interface or you can use code to perform data integration tasks.
Data is made available to users through the AWS Glue Data Catalog and Data engineers can perform ETL actions to populate the data catalog.
AWS Glue studio enables developers to create and run ETL workflows using a visual interface.
Data scientists and analysts can use AWS Glue Databrew to visually manipulate data to enrich and clean it and normalize data without the need to write code or complex scripts.

Glue removes all the tedious and complex tasks associated with establishing an ETL workflow by automatically provisioning and managing the required resources like servers, data storage and runtime compute environments required to run your ETL operations. Glue is a fully managed service, so when you initiate an AWS glue ETL job, the service allocates capacity from warmed up resource pools to run the workload.
As well as provisioning and managing resources, Glue removes the need for you to get involved in installing and maintaining ETL software.
Why use AWS Glue?
Using Glue you can speed up your data integration processes. Instead of multiple users or teams using different ETL tools that might lead to slower data preparation times, organisations that leverage AWS glue across their business can get multiple teams working together using scalable ETL workflows to achieve much faster coordinated results.
Data engineers can test ETL code against development endpoints before deploying it as a fully fledged AWS Glue job.
AWS Glue allows you to automate much of the data integration process. You can use Glue to crawl data sources and in the process understand data formats and metadata at which point Glue can suggest a data storage schema. As part of the process, Glue will generate code for the data transformation and loading ETL processes.
Because AWS Glue is serverless, there is no lead time waiting for network architects or engineers to provision the necessary services. Glue maintains a pool of warmed up servers ready to receive and scale in response to your ETL jobs. This means data engineers, analysts and developers can launch jobs and workflows to get the results they need for your business operations without any delays.
In terms of service costs, you only pay for the AWS Glue resources you consume. There are no additional up front startup or shut down costs.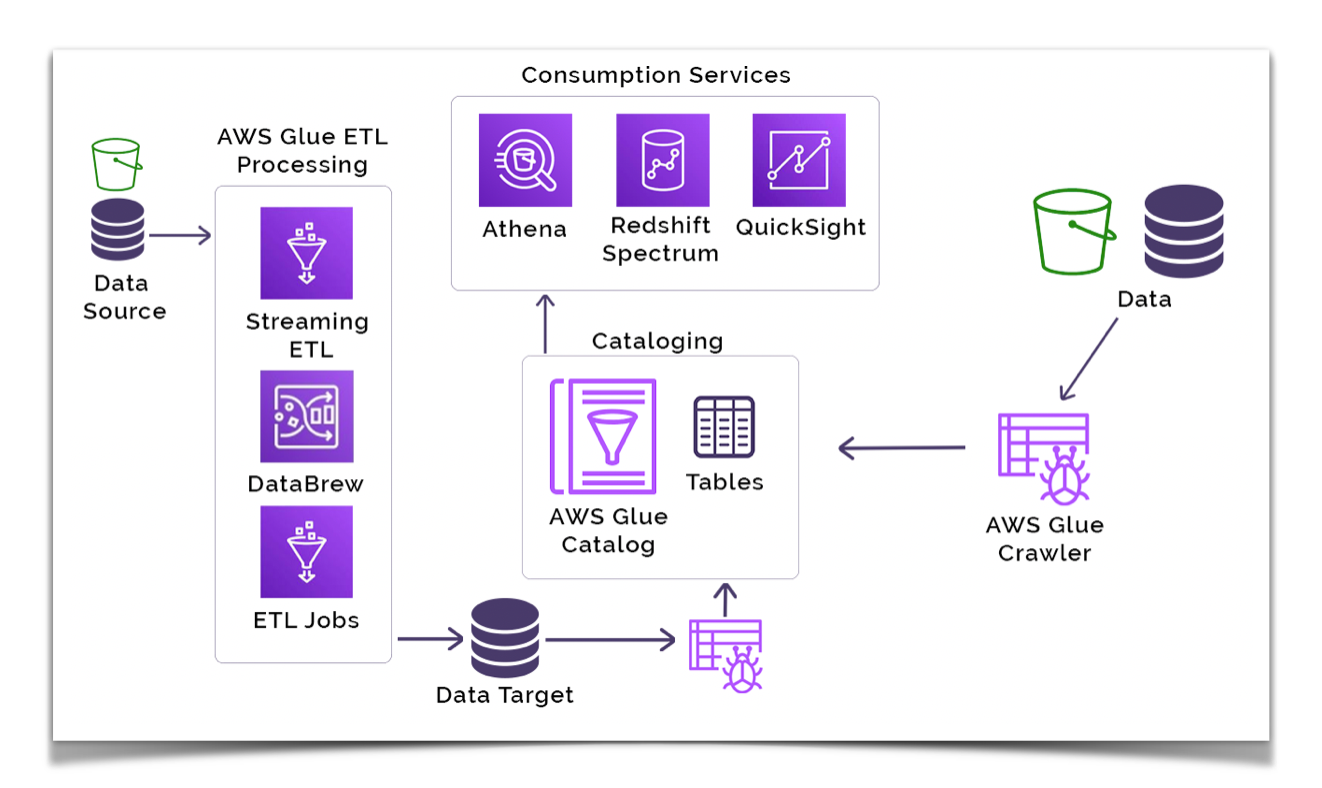
In the above example use case the components that make up the solution are:
Data stores – AWS Glue has the ability to connect to many different types of data sources both on AWS and externally. You can use an AWS Glue crawler to automatically discover and catalog data in the Data Catalog across many different data stores like S3, on premise databases and other cloud providers like GCP.
Data sources and write targets – AWS Glue can read and write to Amazon S3 or databases on AWS or on premises. It can also use a JDBC connection for your external data sources and targets.
AWS Glue natively supports data stored in Amazon Aurora, RDS for MySQL, RDS for Oracle, RDS for PostgreSQL, RDS for SQL Server, Amazon Redshift, DynamoDB and Amazon S3, as well as MySQL, Oracle, Microsoft SQL Server, and PostgreSQL databases in your VPC running on Amazon EC2.
AWS Glue also supports data streams from Amazon MSK, Kinesis Data Streams, and Apache Kafka.
You can also write custom Python or Scala code and import Jar files and custom libraries into your AWS Glue ETL jobs to access data sources not natively supported by Glue.
Glue Data Catalog – As a persistent metadata store, you can use this managed service that is similar to Apache Hive to store, annotate, and share metadata in the AWS Cloud.
The AWS Glue Data Catalog holds all of the information about your tables and table schemas like the physical location of where the data is stored and table properties such as file type, compression type, record size, record count, and more.
AWS Glue Crawler – Using AWS Glue, you can also set up Glue crawlers to scan data in all kinds of data repositories, then classify them and extract schema information, and store the discovered metadata automatically in the Data Catalog. The Data Catalog can then be used to guide ETL operations.
AWS Glue Jobs – The AWS Glue Jobs system provides managed infrastructure to orchestrate your ETL workflow. You can create jobs in AWS Glue that automate the scripts you use to extract, transform, and transfer data to desired locations. Glue Jobs can be scheduled and chained, or they can be activated by events such as the arrival of new data.
AWS Glue DataBrew – Using this visual data preparation tool, you can clean, enrich, format, and normalize your datasets with over 250 built-in transformations. You can create a “recipe” for a dataset using the transformations of your choice, and then reuse that recipe repeatedly as your business continues to collect new data.
AWS Glue Streaming ETL – You can consume real-time data from either an Amazon Kinesis data stream or an Amazon Managed Streaming for Apache Kafka stream. Use the Data Catalog to register the stream as a source. As data comes in from a stream, you are able to apply AWS Glue ETL transformations. Then, you can output your transformed data to an S3 bucket or any another target that is JDBC compatible.
Amazon Athena – Athena is an interactive query service. You can use Athena to analyze data in Amazon S3 with standard SQL queries. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
Amazon Redshift – This is a fully managed AWS data warehouse service in the cloud. You can start with just a few hundred gigabytes of data, and then scale to a petabyte or more. Amazon Redshift also comes with Amazon Redshift Spectrum to help you query data in Amazon S3 without having to move it to Redshift.
Amazon QuickSight – a business intelligence (BI) cloud service, you can create and publish interactive BI dashboards with ML insights from Glue data.
What does AWS Glue cost?
In terms of running ETL jobs, you only pay for the resources you use based on the time you using them ie the time it takes for your job to run. There is an hourly rate based on the number of DPUs (Data Processing Units) are required to run your job. One DPU will provide 4 vCPUs with 16GB of memory
If you are actively coding ETL jobs using development endpoints, there is an hourly charge for the number of DPUs in use with development endpoints requiring at least 2 DPUs
Data Catalog can store up to a million objects for free. Once you exceed the free limit you will be charged $1 per additional 100k objects per month. An object being a table, version, partition or database.
Glue Crawlers attract an hourly rate charge based on the number of DPUs used to run your crawler. Charges are calculated in 1 second increments with a minimum 10 minute charge for crawls. You can avoid using crawlers by populating your Glue catalog using the API.
Databrew is charged by the session which starts as you open a project. A session is calculated at 30 minutes with the initial 40 sessions free for first time users.
AWS Glue Studio is free to use, however the jobs you create and run will consume resources for which you will be charged.
You can estimate your AWS Glue costs using the AWS Glue pricing calculator
Pricing will vary between regions but as a guide at time of writing, most sessions and activity is based on USD$0.44 per DPU per hour
So that’s a quick helicopter view of AWS Glue and what it’s used for.
You should visit the Glue Homepage for more information on the service.
If you are currently building solutions in AWS, Azure, GCP or Kubernetes and not yet using hava.io to visualise your running resources or perform cross platform and cross account searches using a single command, you really should check it out.
You can fully automate the generation and updating of your cloud infrastructure diagrams and security views across one or one thousand cloud accounts, hands free.

There is a free 14 day trial you can take, learn more about Hava using the button below:


